
Real Time data Ingestion in Hbase and Hive using Storm
Introduction
In this tutorial, we will build a solution to ingest real time streaming data into HBase and HDFS. In previous tutorial we have explored generating and processing streaming data with Apache Kafka and Apache Storm. In this tutorial we will create HDFS Bolt & HBase Bolt to read the streaming data from the Kafka Spout and persist in Hive & HBase tables. Prerequisites Lab1 and Lab2Â should be completed successfully with a functional Storm and Kafka Bolt reading data from the Kafka Queue.
Outline
- Introduction
- Prerequisites
- Basics:Hbase
- Basics: Apache Storm
- Step 1: Start Hbase
- Step 2: Create tables in HDFS and Hbase
- Step 3: Launch new Storm topology
- Step 4: Generate events and verify data in HDFS and HBase
- Step 5: Code description
HBase
HBase provides near real-time, random read and write access to tables (or to be more accurate ‘maps’) storing billions of rows and millions of columns. In this case once we store this rapidly and continuously growing dataset from Internet of Things (IoT), we will be able to do super fast lookup for analytics irrespective of the data size.
Apache Storm
Apache Storm is an Open Source distributed, reliable, fault–tolerant system for real time processing of large volume of data. Spout and Bolt are the two main components in Storm, which work together to process streams of data.
- Spout: Works on the source of data streams. In the “Truck Events” use case, Spout will read data from Kafka topics.
-
Bolt: Spout passes streams of data to Bolt which processes and persists  it to a data store or sends it downstream to another Bolt. In this tutorial, you will learn the following topics:
- To configure Storm Bolt.
- Persisting data in HBase and Hive.
- Verify data in HDFS and HBase. Step 1: Start HBase
-
View the HBase Services page Started by logging into Ambari as admin/admin. From the previous tutorials: HDFS, Hive, YARN, Kafka and Storm should already be running but HBase may be down. From the Dashboard page of Ambari, click on HBase from the list of installed services.
-
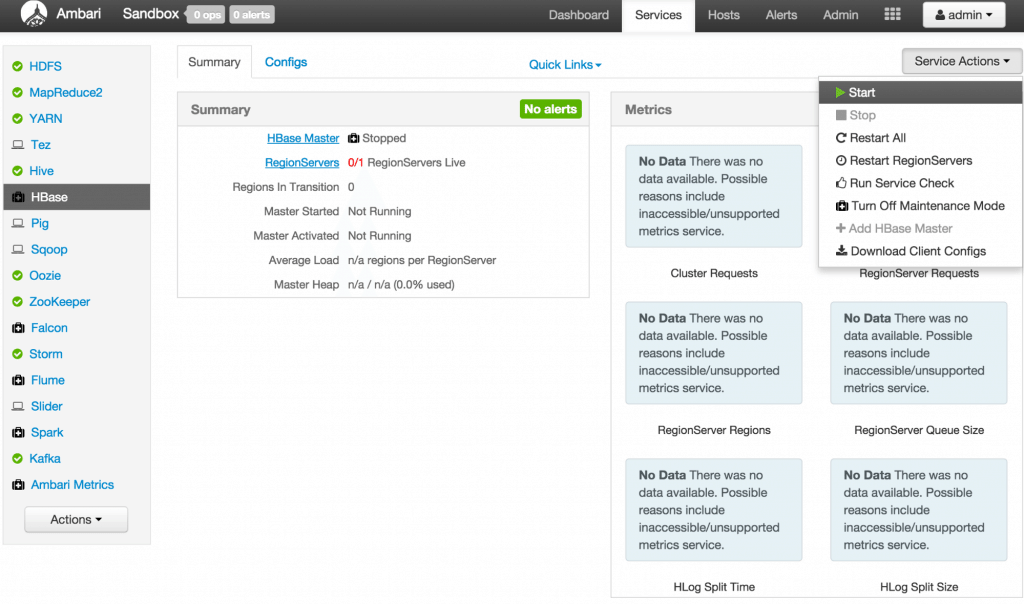
** Start HBase** From the HBase page, click on Service Actions -> Start
 Check the box and click on Confirm Start:
Check the box and click on Confirm Start: 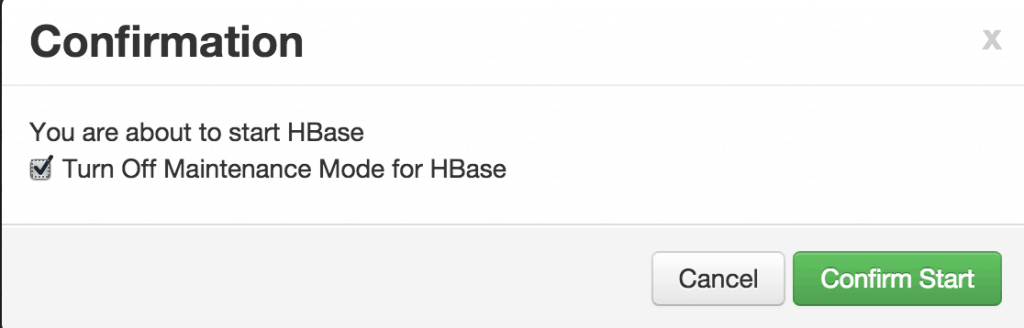 Wait for HBase to start (It may take a few minutes to turn green)
Wait for HBase to start (It may take a few minutes to turn green)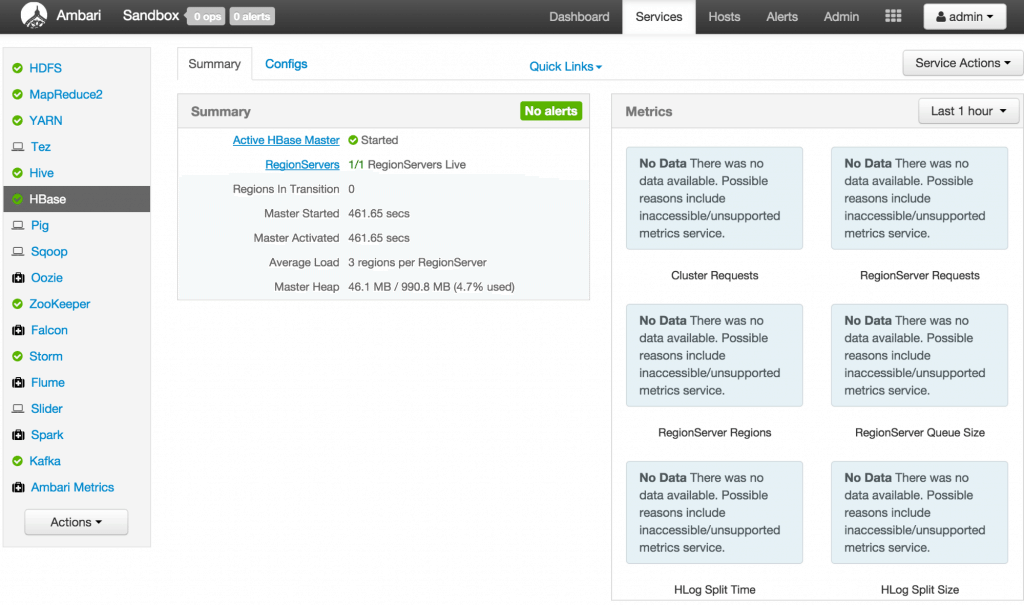 You can use the Ambari dashboard to check status of other components too. If HDFS, Hive, YARN, Kafka, Storm or HBase are down, you can start them in the same way: by selecting the service and then using the Service Actions to start it. The remaining components do not have to be up. (Oozie can be stopped to save memory, as it is not needed for this tutorial) Step 2:Â Create tables in HDFS & HBase.
You can use the Ambari dashboard to check status of other components too. If HDFS, Hive, YARN, Kafka, Storm or HBase are down, you can start them in the same way: by selecting the service and then using the Service Actions to start it. The remaining components do not have to be up. (Oozie can be stopped to save memory, as it is not needed for this tutorial) Step 2:Â Create tables in HDFS & HBase. -
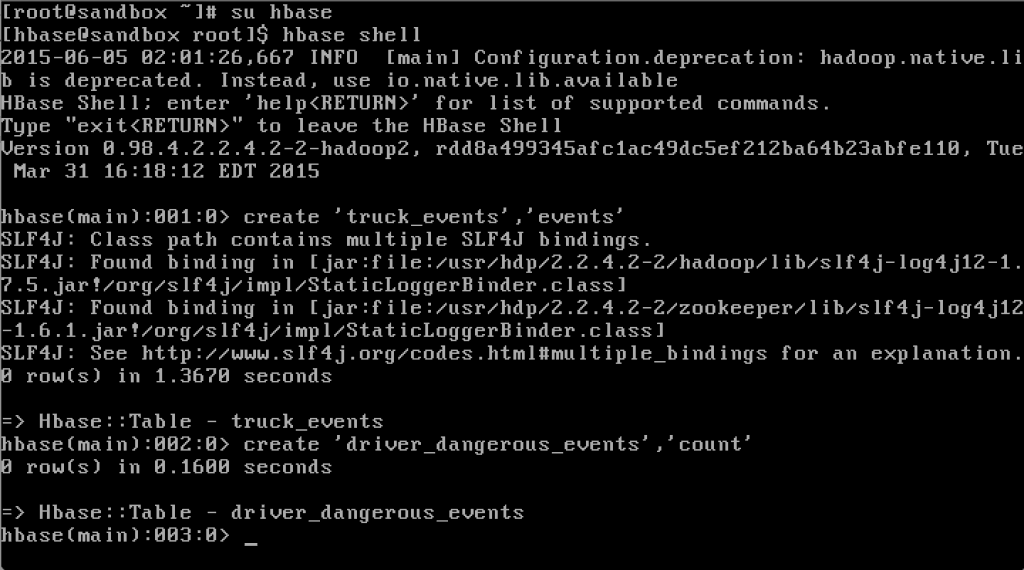
Creating HBase tables We will be working with 2 Hbase tables in this tutorial. The first table stores all events generated and the second stores the ‘driverId’ and non-normal events count.
[hbase@sandbox root]$ hbase shell
hbase(main):001:0> create 'truck_events', 'events'
hbase(main):002:0> create 'driver_dangerous_events', 'count'
hbase(main):003:0> list
hbase(main):004:0>
 Next, we will create Hive tables. Â Â 2. Â Creating Hive tables Open the Hive view in Ambari in a browser and copy the below script into the query editor and click Execute: http://localhost:8080/#/main/views/HIVE/0.2.0/MyHive
Next, we will create Hive tables. Â Â 2. Â Creating Hive tables Open the Hive view in Ambari in a browser and copy the below script into the query editor and click Execute: http://localhost:8080/#/main/views/HIVE/0.2.0/MyHive
create table truck_events_text_partition
(driverId string,
truckId string,
eventTime timestamp,
eventType string,
longitude double,
latitude double)
partitioned by (eventDate string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
This creates the Hive table to persist all events generated. The table is partitioned by date.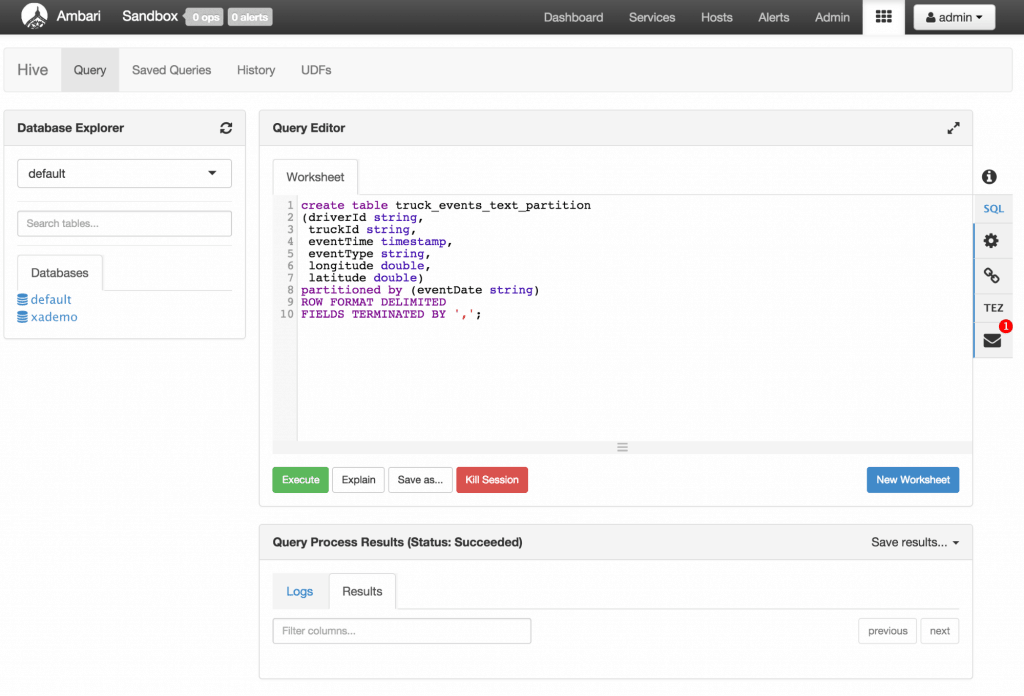 Verify that the table has been properly created by refreshing the Database Explorer. Under Databases, click default to expand this table and the new table should appear. Clicking on the List icon next to truck_events_text_partition shows that the table was created but empty.
Verify that the table has been properly created by refreshing the Database Explorer. Under Databases, click default to expand this table and the new table should appear. Clicking on the List icon next to truck_events_text_partition shows that the table was created but empty. 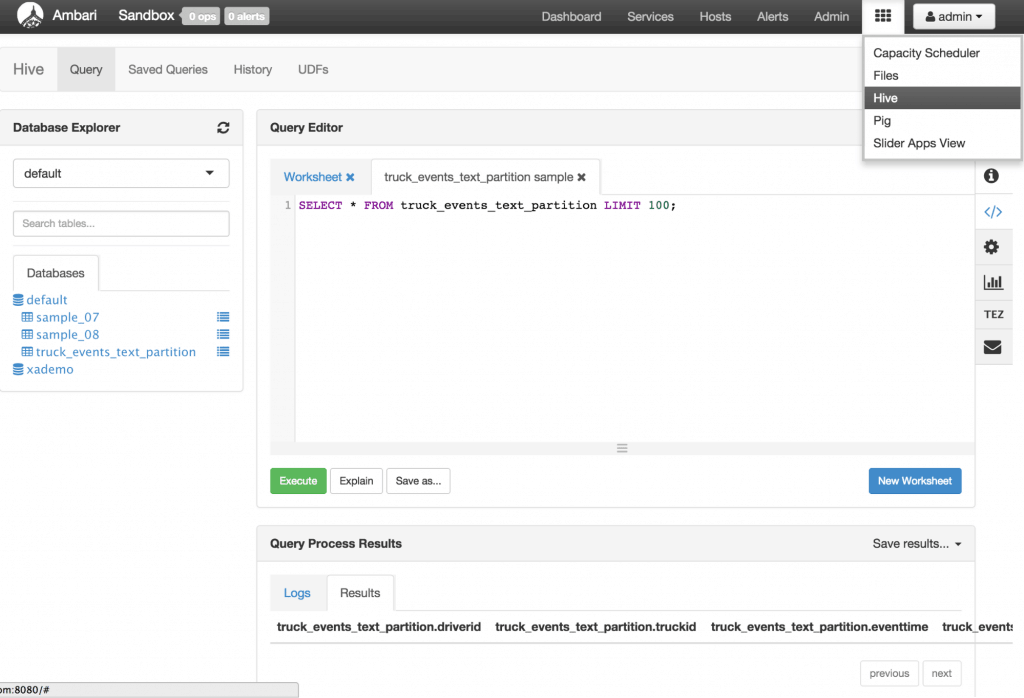     3.  Creating ORC ‘truckevent’ Hive tables The Optimized Row Columnar (ORC) file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data. Syntax for ORC tables: CREATE TABLE … STORED AS ORC ALTER TABLE … [PARTITION partition_spec] SET FILEFORMAT ORC Note: This statement only works on partitioned tables. If you apply it to flat tables, it may cause query errors. Next let’s create the ‘truckevent’ table as per the above syntax. Paste the below into the worksheet of the Hive view and click Execute
    3.  Creating ORC ‘truckevent’ Hive tables The Optimized Row Columnar (ORC) file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data. Syntax for ORC tables: CREATE TABLE … STORED AS ORC ALTER TABLE … [PARTITION partition_spec] SET FILEFORMAT ORC Note: This statement only works on partitioned tables. If you apply it to flat tables, it may cause query errors. Next let’s create the ‘truckevent’ table as per the above syntax. Paste the below into the worksheet of the Hive view and click Execute
create table truck_events_text_partition_orc
(driverId string,
truckId string,
eventTime timestamp,
eventType string,
longitude double,
latitude double)
partitioned by (eventDate string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
stored as orc tblproperties ("orc.compress"="NONE");
Refresh the Database Explorer and you should see the new table appear under default: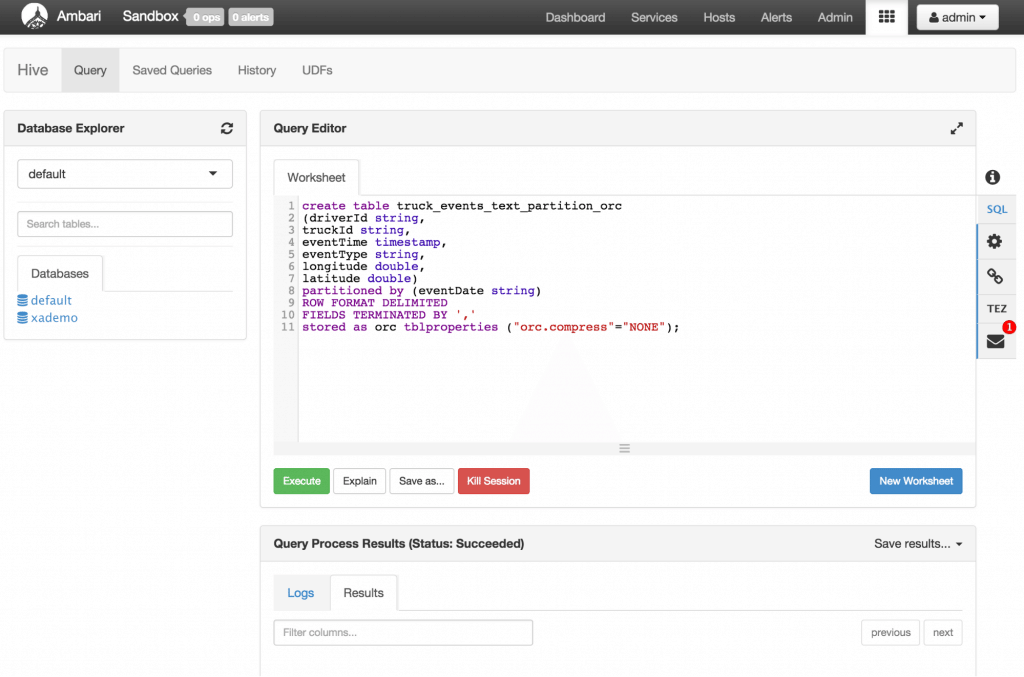 The data in ‘truck_events_text_partition_orc’ table can be stored with ZLIB, Snappy, LZO compression options. This can be set by changing tblproperties (“orc.compress”=”NONE”)option in the query above.   4.  Set permissions on /tmp/hive
The data in ‘truck_events_text_partition_orc’ table can be stored with ZLIB, Snappy, LZO compression options. This can be set by changing tblproperties (“orc.compress”=”NONE”)option in the query above.   4.  Set permissions on /tmp/hive
**chmod -R 777 /tmp/hive/**
####
####
Step 3: Launch new Storm topology
Recall that the source code is under /opt/TruckEvents/Tutorials-master/src directory and pre-compiled jars are under the /opt/TruckEvents/Tutorials-master/target directory (Optional) If you would like to modify/run the code:
- refer to Appendix A for the steps to run maven to compile the jars to the target subdir from terminal command line
-
refer to Appendix B for the steps to enable VNC (i.e. ‘remote desktop’) access on your sandbox and open/compile the code using Eclipse If its still running, deactivate or kill the previous Storm topology using the Storm UI as shown in the screenshots below:
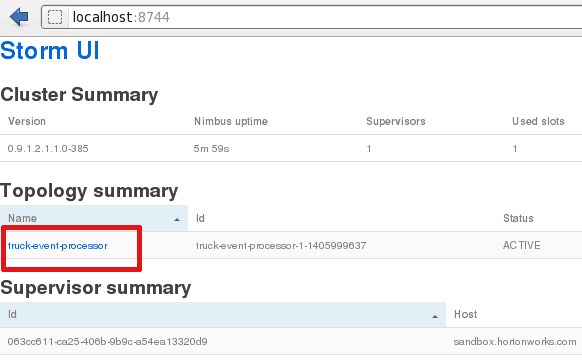 Storm User view: Alternatively you shall see a topology runnning in your Storm User View as well.
Storm User view: Alternatively you shall see a topology runnning in your Storm User View as well. Deactivate or kill:
Deactivate or kill: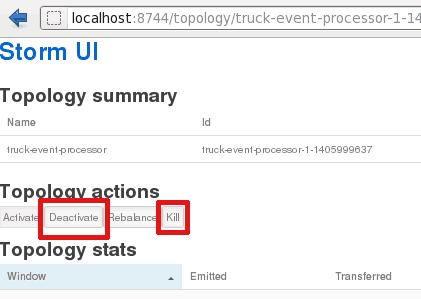 Deactivate
Deactivate Kill
Kill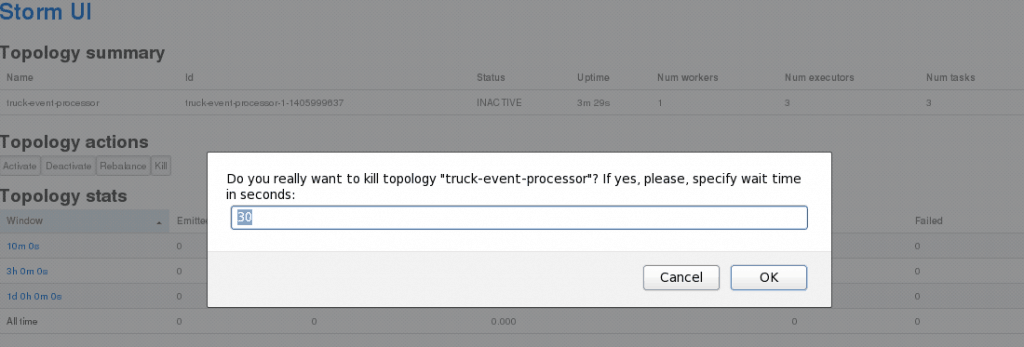
-
Alternatively, you can kill the topology using Storm User View as well.
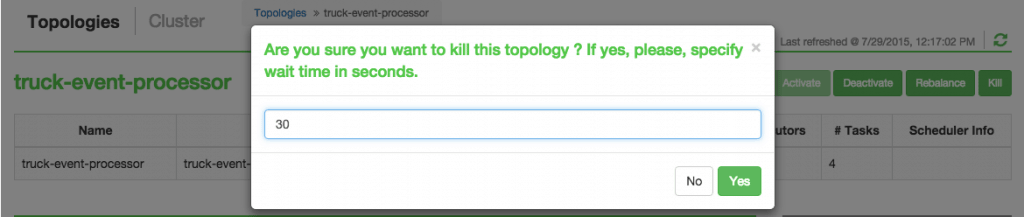 The Storm topology can be deactivated/killed from the Storm UI as above or via shell: storm kill TruckEventProcessingTopology   1.  Loading new Storm topology. Execute the Storm ‘jar’ command to create a new Topology from Tutorial# 3 after the code has been compiled.
The Storm topology can be deactivated/killed from the Storm UI as above or via shell: storm kill TruckEventProcessingTopology   1.  Loading new Storm topology. Execute the Storm ‘jar’ command to create a new Topology from Tutorial# 3 after the code has been compiled.[root@sandbox Tutorials-master]# storm jar target/Tutorial-1.0-SNAPSHOT.jar com.hortonworks.tutorials.tutorial3.TruckEventProcessingTopology
You should see that it successfully submitted the topology: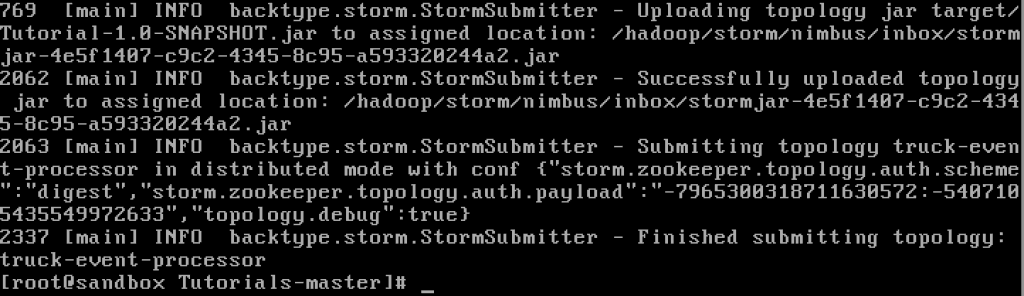 The topology should also show up on Storm User View: You shall see here that Kafka Spout has started writing to HDFSÂ and HBase.
The topology should also show up on Storm User View: You shall see here that Kafka Spout has started writing to HDFSÂ and HBase.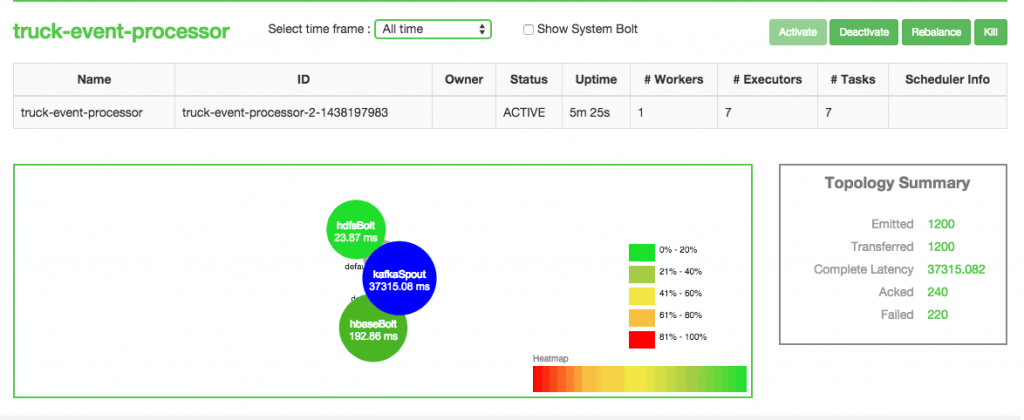

####
Step 4: Generate Events and Verify Data in HDFS and HBase
- Start the ‘TruckEventsProducer’ Kafka Producer and verify that the data has been persisted by using the Storm Topology view.
[root@sandbox Tutorials-master]# java -cp target/Tutorial-1.0-SNAPSHOT.jar com.hortonworks.tutorials.tutorial1.TruckEventsProducer sandbox.hortonworks.com:6667 sandbox.hortonworks.com:2181
Verify in the Storm UI or Storm User View to verify the Bolt section that HDFS/HBase tuples are being executed and acked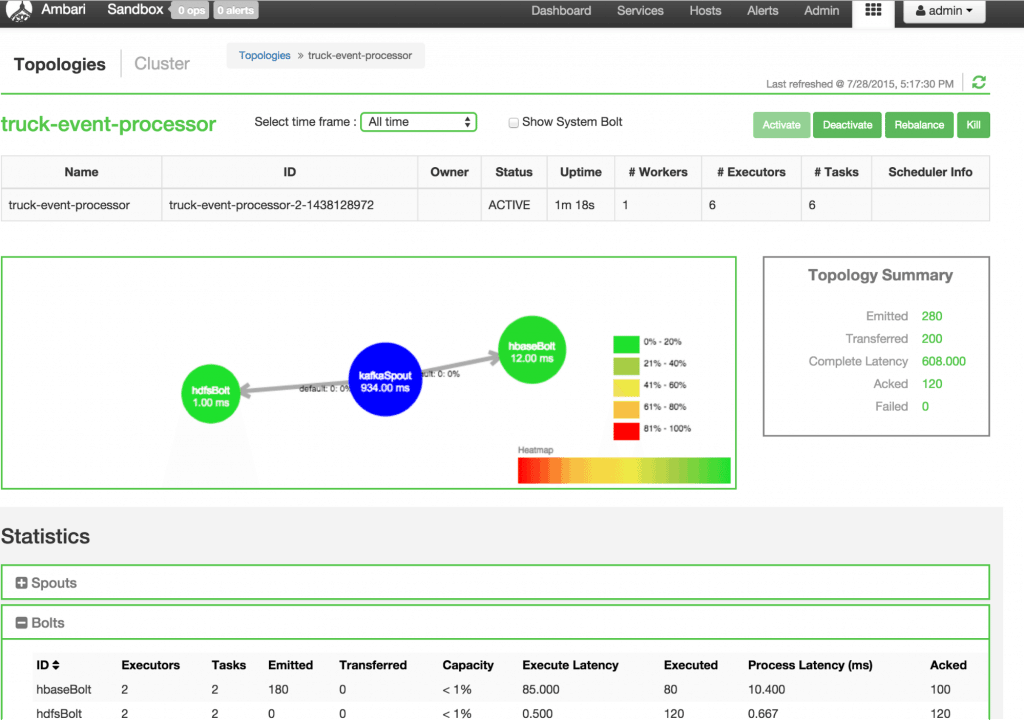 2. Â Verify that the data is in HDFS by opening the Ambari Files view: http://localhost:8080/#/main/views/FILES/0.1.0/MyFiles With the default settings for HDFS, users will see the data written to HDFS once in every few minutes.
2. Â Verify that the data is in HDFS by opening the Ambari Files view: http://localhost:8080/#/main/views/FILES/0.1.0/MyFiles With the default settings for HDFS, users will see the data written to HDFS once in every few minutes. Drill down into /truck-events-v4/staging dir in HDFS
Drill down into /truck-events-v4/staging dir in HDFS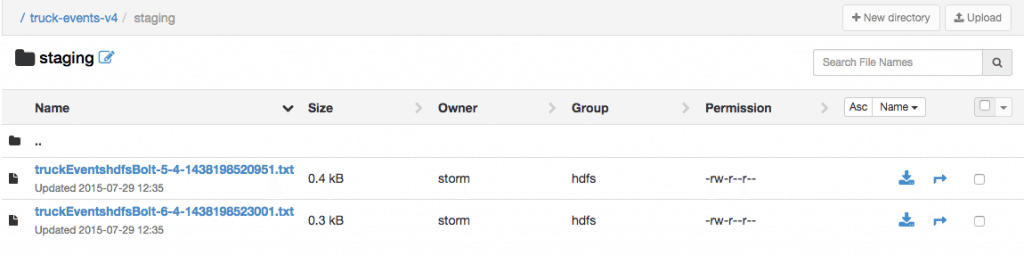 Click on one of the txt files and confirm that it contains the events:
Click on one of the txt files and confirm that it contains the events: 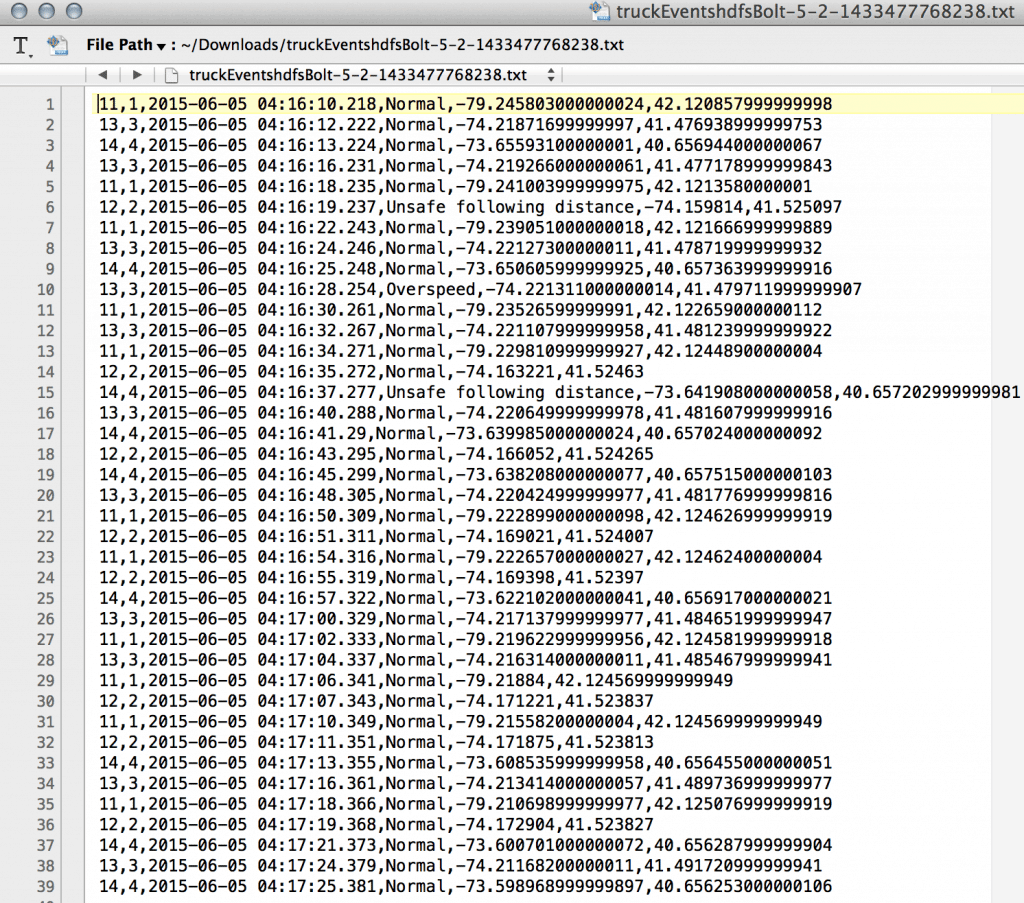
-
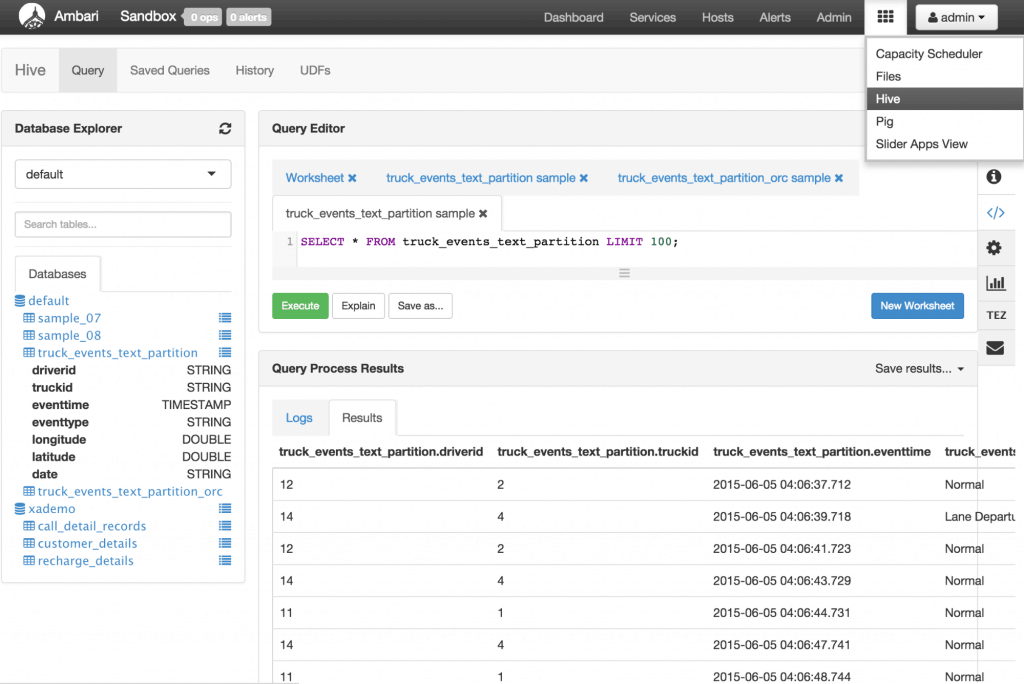
Verify data in Hive by navigating to the Hive view, expanding the default database and and clicking the List icon next to truck_events_text_partition table
- You can press Control-C to stop the Kafka producer (i.e keep Control key pressed and then press C)
-
Verify that the data is in HBase by executing the following commands in HBase shell:
[root@sandbox Tutorials-master]# hbase shell hbase(main):001:0> list hbase(main):002:0> count ‘truck_events’ 366 row(s) in 0.3900 seconds => 366 hbase(main):003:0> count ‘driver_dangerous_events’ 3 row(s) in 0.0130 seconds => 3 hbase(main):004:0> exit
The ‘driver_dangerous_events’ table is updated upon every violation.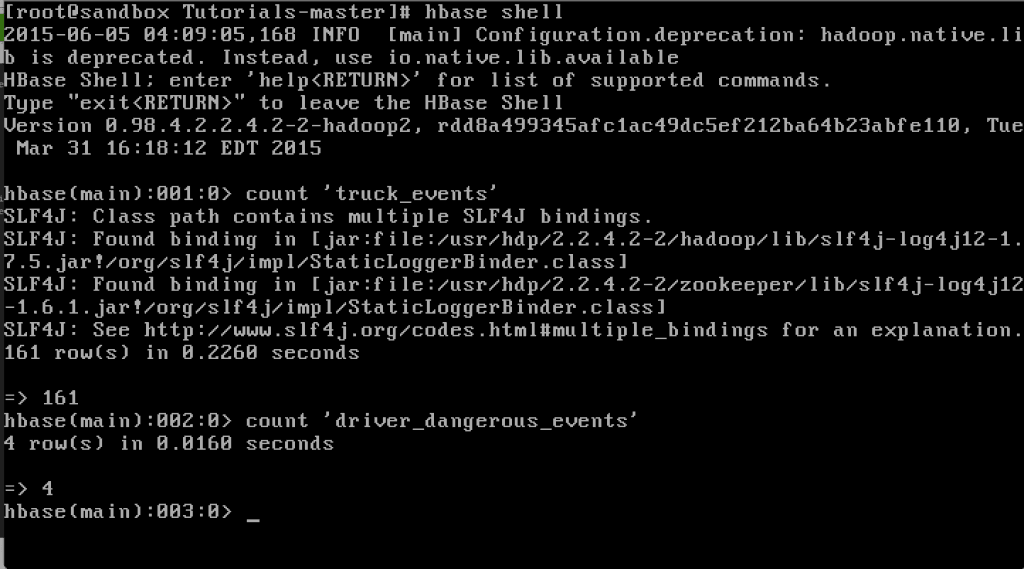
-
Next let’s populate the data into ORC table for interactive query by Excel (or any BI tool) via ODBC over Hive/Tez. Open the Hive view and enter the below and click Execute.
INSERT OVERWRITE TABLE truck_events_text_partition_orc partition (date)
select * from truck_events_text_partition;
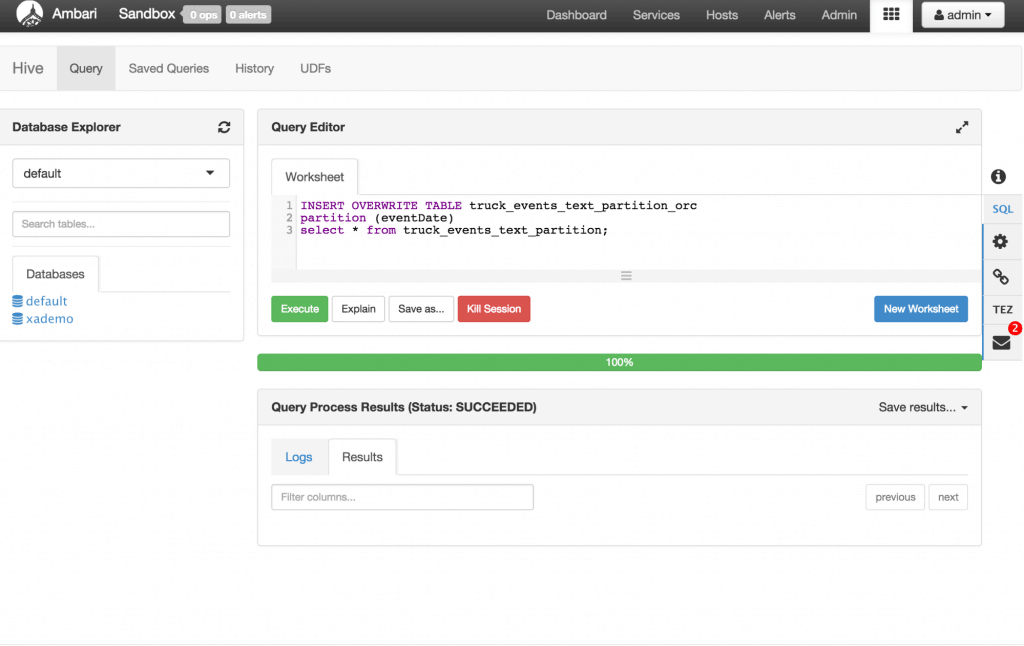 Notice that this launches a Tez job in the background. You can get more details on this using the Yarn resource manager UI. You can find for this under the link under Ambari -> Yarn -> Quick links but will be similar to http://localhost:8088/cluster
Notice that this launches a Tez job in the background. You can get more details on this using the Yarn resource manager UI. You can find for this under the link under Ambari -> Yarn -> Quick links but will be similar to http://localhost:8088/cluster Now query the ORC table by clicking the List icon next to it under Databases and notice it is also now populated
Now query the ORC table by clicking the List icon next to it under Databases and notice it is also now populated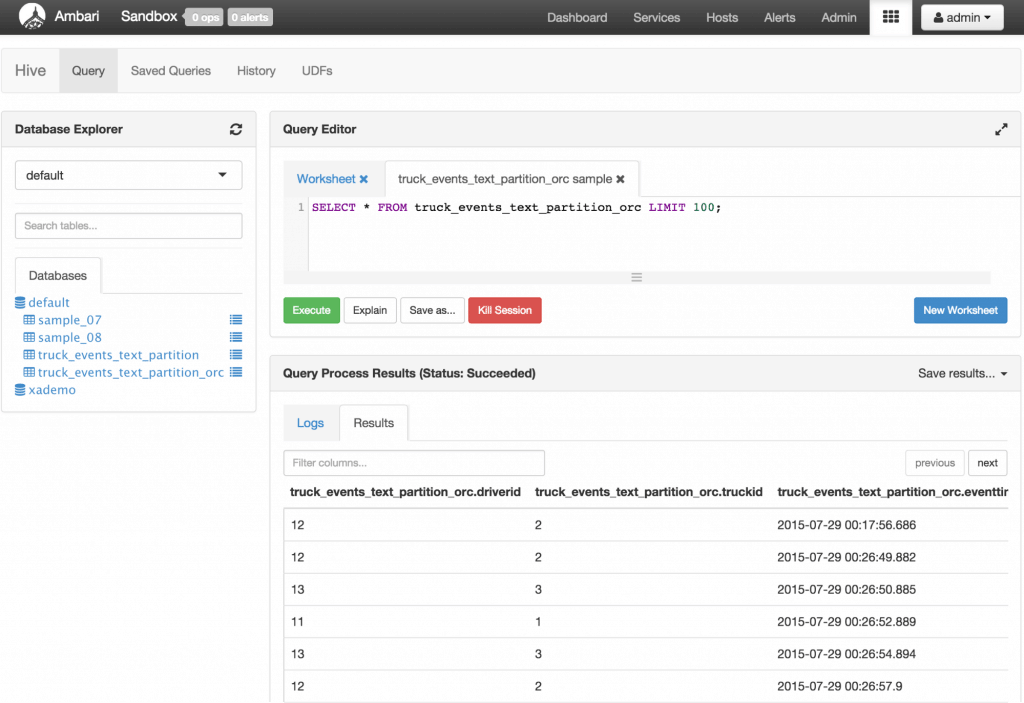
-
Once done, stop the Storm topology The Storm topology can be deactivated/killed from the Storm UI or
storm kill TruckEventProcessingTopology
Code Description 1. Â BaseTruckEventTopology.java
topologyConfig.load(ClassLoader.getSystemResourceAsStream(configFileLocation));
This is the base class, where the topology configuration is initialized from the /resource/truck_event_topology.properties files. 2. Â FileTimeRotationPolicy.java This implements the file rotation policy after a certain duration. public FileTimeRotationPolicy(float count, Units units) { this.maxMilliSeconds = (long) (count * units.getMilliSeconds()); }
@Override
public boolean mark(Tuple tuple, long offset) {
// The offsett is not used here as we are rotating based on time
long diff = (new Date()).getTime() - this.lastCheckpoint;
return diff >= this.maxMilliSeconds;
}
-
 LogTruckEventsBolt.java LogTruckEvent Spout logs the Kafka messages received from the Kafka Spout to the log files under /var/log/storm/worker-*.log
public void execute(Tuple tuple) { LOG.info(tuple.getStringByField(TruckScheme.FIELD_DRIVER_ID) + “,” + tuple.getStringByField(TruckScheme.FIELD_TRUCK_ID) + “,” + tuple.getValueByField(TruckScheme.FIELD_EVENT_TIME) + “,” + tuple.getStringByField(TruckScheme.FIELD_EVENT_TYPE) + “,” + tuple.getStringByField(TruckScheme.FIELD_LATITUDE) + “,” + tuple.getStringByField(TruckScheme.FIELD_LONGITUDE)); }
-
 TruckScheme.java This is the deserializer provided to the Kafka Spout to deserialize Kafka’s byte message streams to Values objects.
public List
Timestamp eventTime = Timestamp.valueOf(pieces[0]); String truckId = pieces[1]; String driverId = pieces[2]; String eventType = pieces[3]; String longitude= pieces[4]; String latitude  = pieces[5]; return new Values(cleanup(driverId), cleanup(truckId), eventTime, cleanup(eventType), cleanup(longitude), cleanup(latitude));
} catch (UnsupportedEncodingException e) { LOG.error(e); throw new RuntimeException(e); }
}
-
 HiveTablePartitionAction.java This creates Hive partitions based on timestamp and loads the data by executing the Hive DDL statements.
public void loadData(String path, String datePartitionName, String hourPartitionName ) {
String partitionValue = datePartitionName + “-“ + hourPartitionName;
LOG.info(“About to add file[”+ path + “] to a partitions[“+partitionValue + “]”);
StringBuilder ddl = new StringBuilder(); ddl.append(“ load data inpath “) .append(“ ‘”).append(path).append(“’ “) .append(“ into table “) .append(tableName) .append(“ partition “).append(“ (date=’”).append(partitionValue).append(“’)”);
startSessionState(sourceMetastoreUrl);
The data is stored in the partitioned ORC tables using the following method.
String ddlORC = “INSERT OVERWRITE TABLE “ + tableName + “_orc SELECT * FROM “ +tableName;
try { execHiveDDL(“use “ + databaseName); execHiveDDL(ddl.toString()); execHiveDDL(ddlORC.toString()); } catch (Exception e) { String errorMessage = “Error exexcuting query[“+ddl.toString() + “]”; LOG.error(errorMessage, e); throw new RuntimeException(errorMessage, e); } }
-
 TruckEventProcessingTopology.java This creates a connection to HBase tables and access data within the prepare() function.
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { … this.connection = HConnectionManager.createConnection(constructConfiguration()); this.eventsCountTable = connection.getTable(EVENTS_COUNT_TABLE_NAME); this.eventsTable = connection.getTable(EVENTS_TABLE_NAME); }
… }
Data to be stored is prepared in the constructRow() function using put.add().
private Put constructRow(String columnFamily, String driverId, String truckId,
Timestamp eventTime, String eventType, String latitude, String longitude)
{
String rowKey = consructKey(driverId, truckId, eventTime);
...
put.add(CF_EVENTS_TABLE, COL_DRIVER_ID, Bytes.toBytes(driverId));
put.add(CF_EVENTS_TABLE, COL_TRUCK_ID, Bytes.toBytes(truckId));
...
}
This executes the getInfractionCountForDriver() to get the count of events for a driver using driverID and stores the data in HBase with constructRow() function.
public void execute(Tuple tuple)
{
...
long incidentTotalCount = getInfractionCountForDriver(driverId);
...
Put put = constructRow(EVENTS_TABLE_NAME, driverId, truckId, eventTime, eventType,
latitude, longitude);
this.eventsTable.put(put);
...
incidentTotalCount = this.eventsCountTable.incrementColumnValue(Bytes.toBytes(driverId), CF_EVENTS_COUNT_TABLE,
...
}
-
 TruckEventProcessingTopology.java HDFS and HBase Bolt configurations created within configureHDFSBolt() and configureHBaseBolt() respectively.
public void configureHDFSBolt(TopologyBuilder builder) {
HdfsBolt hdfsBolt = new HdfsBolt() .withFsUrl(fsUrl) .withFileNameFormat(fileNameFormat) .withRecordFormat(format) .withRotationPolicy(rotationPolicy) .withSyncPolicy(syncPolicy) .addRotationAction(hivePartitionAction);
} public void configureHBaseBolt(TopologyBuilder builder) { TruckHBaseBolt hbaseBolt = new TruckHBaseBolt(topologyConfig); builder.setBolt(HBASE_BOLT_ID, hbaseBolt, 2).shuffleGrouping(KAFKA_SPOUT_ID); }
Appendix A:Â Updating Tutorials-master Project
-
Copy /etc/hbase/conf/hbase-site.xml to src/main/resources/ directory
[root@sandbox ~]# cd /opt/TruckEvents/Tutorials-master [root@sandbox ~]# cp /etc/hbase/conf/hbase-site.xml src/main/resources/
-
Check pom.xml to ensure it includes the below dependencies (check after line 104)
xerces xercesImpl 2.9.1 xalan xalan 2.7.1 org.htrace htrace-core 3.0.4 org.apache.hadoop hadoop-hdfs 2.6.0 -
recompile the Maven project. This may run for 10+ min
[root@sandbox ~]# mvn clean package
The maven build should succeed Appendix B: Enabling remote desktop on sandbox and setting up Storm topology as Eclipse project
- Setup Ambari VNC service on the sandbox to enable remote desktop via VNC and install eclipse using steps here https://github.com/hortonworks-gallery/ambari-vnc-service#setup-vnc-service
- Import code as Eclipse project using steps here: https://github.com/hortonworks-gallery/ambari-vnc-service#getting-started-with-storm-and-maven-in-eclipse-environment Back Next

Saptak Sen
If you enjoyed this post, you should check out my book: Starting with Spark.